Game-RL: Synthesizing Multimodal Verifiable Game Data to Boost VLMs' General Reasoning
ICLR 2026
1Fudan University
2Shanghai Innovation Institute
3SUSTech
* Equal contribution † Corresponding authors
News
- [2026/04] Princeton University uses our GameQA dataset in their Vero project.
- [2026/03] National University of Singapore uses our games in the Gym-V platform.
- [2026/02] Alibaba Group and Shanghai Jiao Tong University uses our GameQA-140K dataset at scale in the DeepVision-103K dataset, which accounts for around 50% of its "visual logic problems".
- [2026/01] Shanghai AI Lab uses our GameQA-140K dataset at scale in the MMFineReason dataset, which accounts for 87.65% of its "Puzzle/Game" samples.
- [2026/01] THUML and ByteDance Seed use our Sokoban code for the synthesis of the Sokoban task samples in VisWorld-Eval (and the training data).
- 🎉 [2026/01] Our work has been accepted by ICLR 2026! 🎉🎉🎉
- [2025/11] DeepWisdom uses the maze-like games in our GameQA dataset in the VR-Bench benchmark, which evaluates video models' reasoning.
- [2025/11] Shanghai Innovation Institute uses the games in our GameQA dataset for image editing reasoning tasks ("game-world scenarios"), developing the UniREditBench benchmark and the UniREdit-Data-100K training data.
Abstract
Vision-language reinforcement learning (RL) has primarily focused on narrow domains (e.g. geometry or chart reasoning). This leaves broader training scenarios and resources underexplored, limiting the exploration and learning of Vision Language Models (VLMs) through RL. We find video games inherently provide rich visual elements and mechanics that are easy to verify. To fully leverage the multimodal and verifiable rewards in video games, we propose Game-RL, constructing diverse game tasks for RL training to boost VLMs' general reasoning ability. To obtain training data, we propose Code2Logic, a novel approach that adapts game code to synthesize reasoning data with unlimited examples and controllable difficulty gradation, thus obtaining the GameQA dataset of 30 games and 158 verifiable tasks. Remarkably, RL training solely on GameQA enables multiple VLMs to generalize across 7 diverse out-of-domain vision-language benchmarks, demonstrating the value of Game-RL for enhancing VLMs' general reasoning. Furthermore, game data provides improvements comparable to general multimodal reasoning datasets (e.g. geometry/chart). More importantly, scaling up game diversity or game data volume consistently improves VLMs' generalizable reasoning capabilities. Our findings highlight scaling reinforcement learning in game environments as a promising direction for enhancing generalizable multimodal reasoning in foundation models.
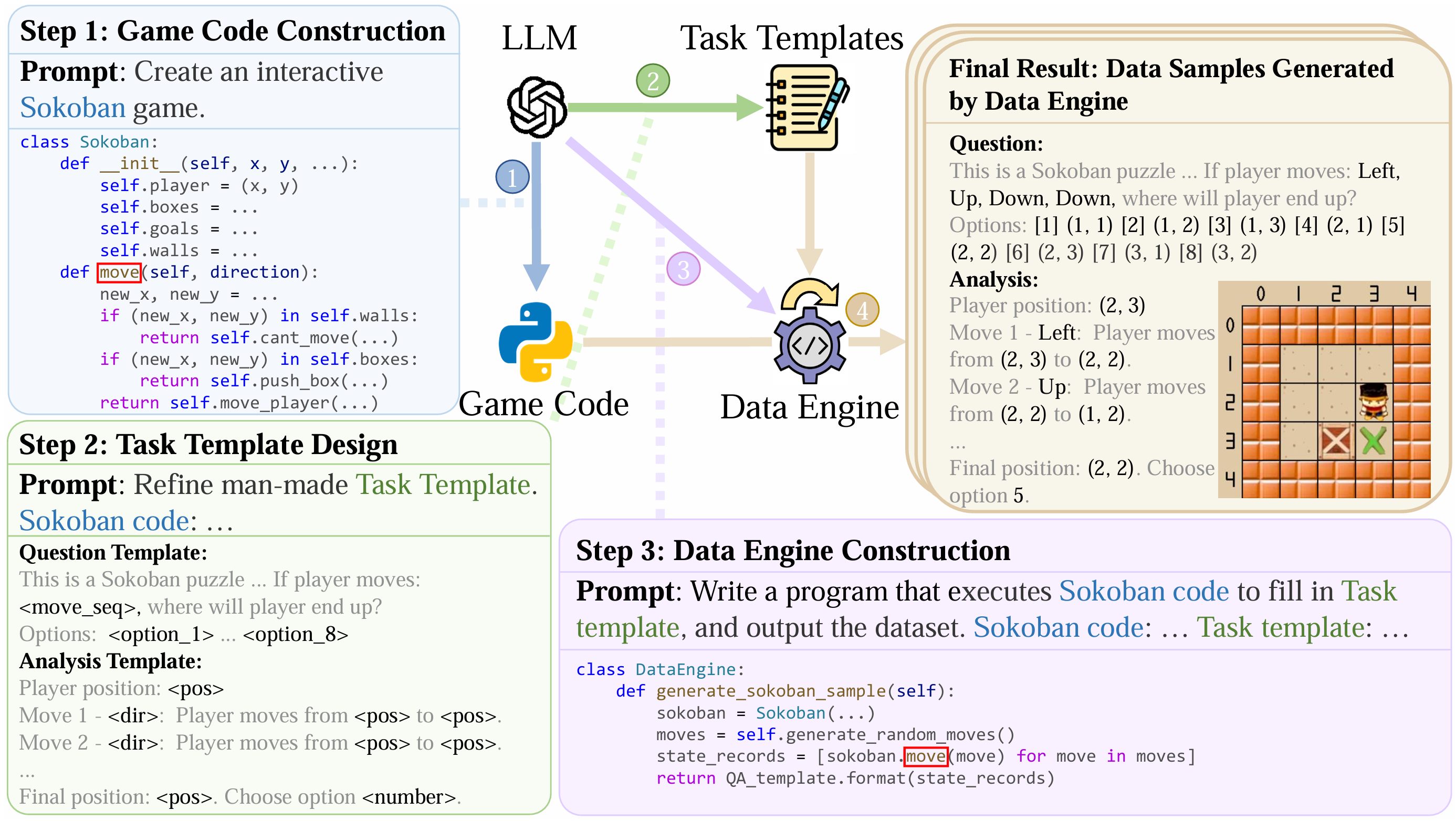
Code2Logic Approach
The Code2Logic approach involves three main steps:
1. Using LLMs to construct game code of the selected game (Sokoban).
2. LLM-assisted design of the task templates including question and analysis templates based on the generated game code. Each task template condenses one type of reasoning pattern in the game.
3. Using LLMs to construct a data engine that directly reuses the core game code from the first step, including functions like move.
After these main steps, the data engine is executed to fill in the task templates developed in Step 2 and generate data samples.
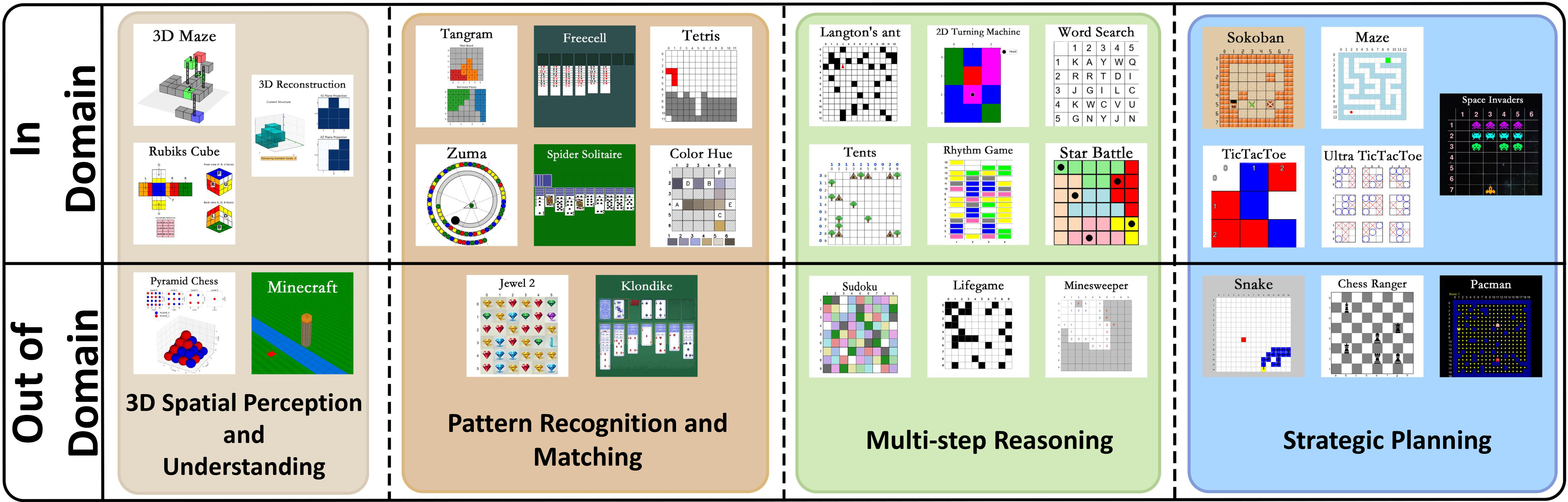
GameQA Dataset
Our GameQA dataset provides diverse verifiable game tasks along with controllable difficulty, extending RL training scenarios for VLMs to the domain of video games.
It encompasses 30 different games classified into 4 categories based on the core capabilities required to solve game tasks. Four games from different categories and their example data samples are illustrated in the image below. The GameQA data samples are also reasonably graded by difficulty (see 🤗 GameQA-140K).

Key Findings
😎 Game-RL leads to generalizable multimodal reasoning improvements
RL Training solely on game data (GameQA) enables three VLMs (Qwen2.5-VL, InternVL2.5, InternVL3) to achieve consistent performance improvements across 7 diverse vision reasoning benchmarks, demonstrating strong out-of-domain generalization. These results suggest that the models have successfully learned transferable visual understanding and reasoning abilities through Game-RL.
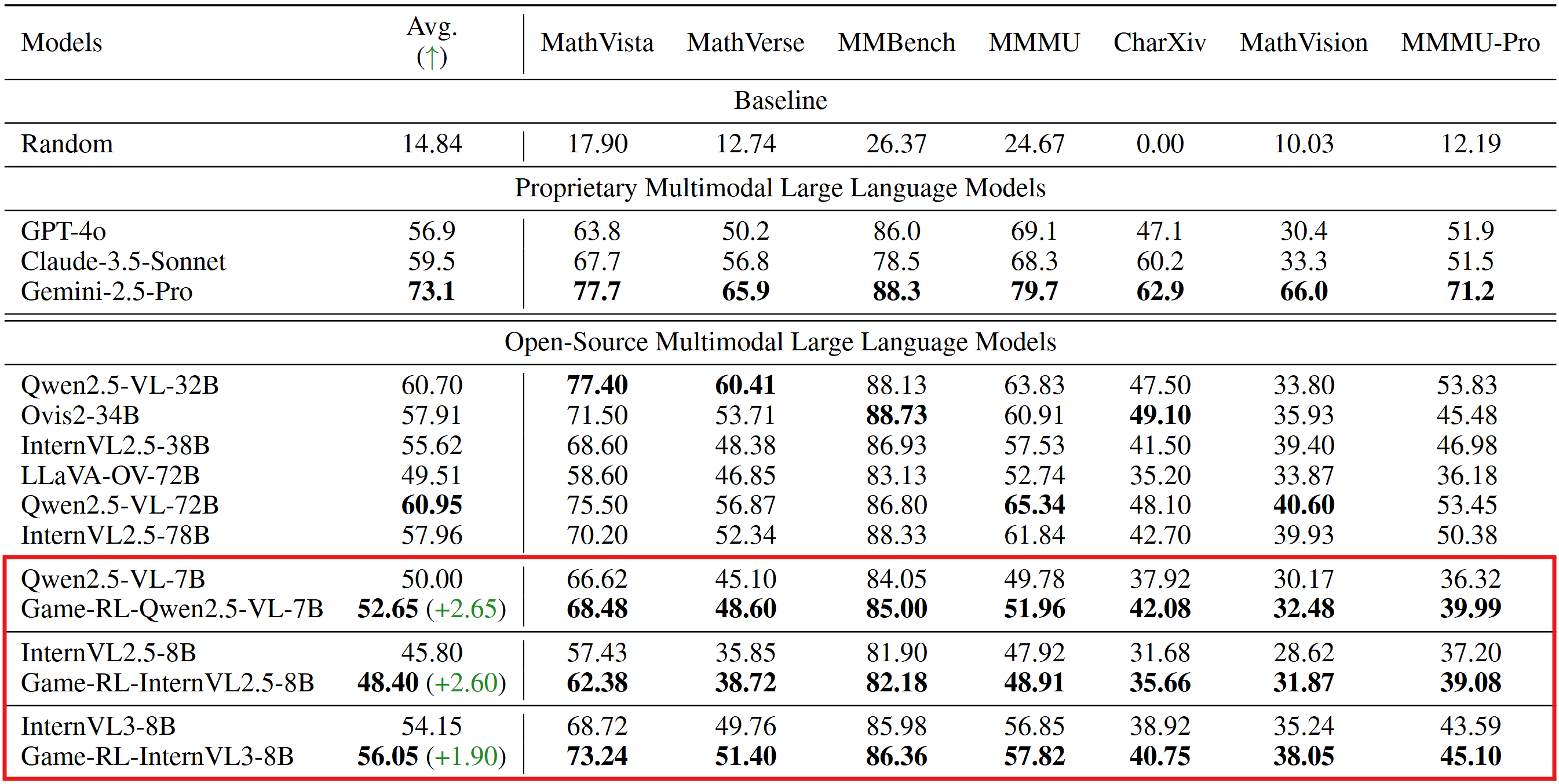
💪 Game data is competitive to geometry datasets
Based on Qwen2.5-VL-7B, we applied the same training method on 5k GameQA samples, 8k samples from MAVIS, 8k Multimodal-Open-R1 samples, 8k MultiMath samples respectively, to conduct comparative training.
The GameQA-trained model is competitive compared to its counterparts trained on geometry or function data, where general vision benchmarks would be considered in-domain. These results suggest that GameQA enables stronger out-of-domain generalization, even when using less data from a mismatched domain.
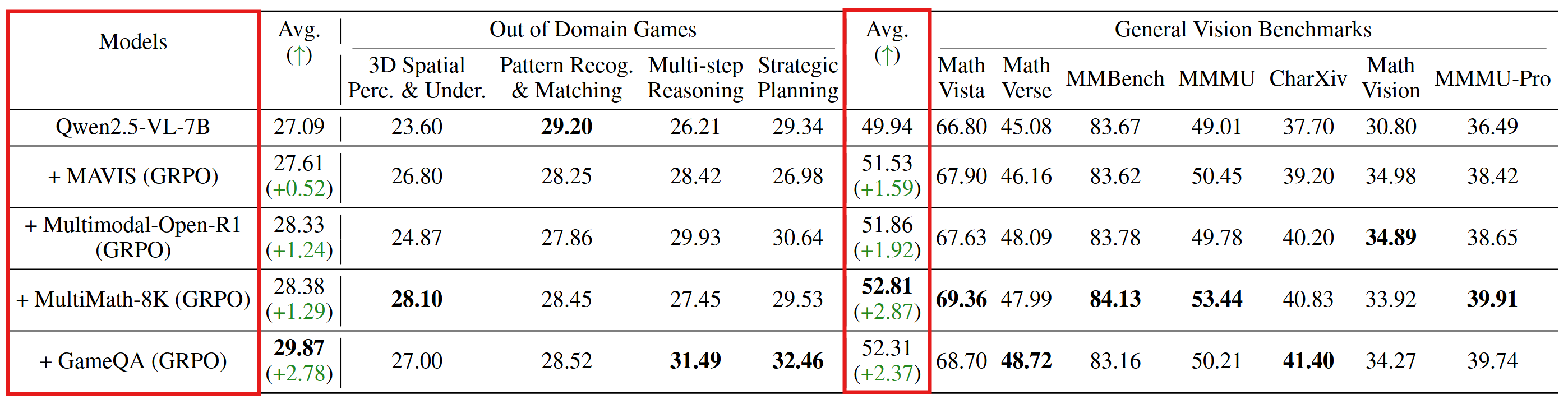
📈 Scaling Effects: Game Diversity & Data Volume
Game Diversity: Scaling up game diversity (e.g., 4 games → 20 games) makes better generalization, enabling the model to acquire more robust visual understanding and reasoning abilities.
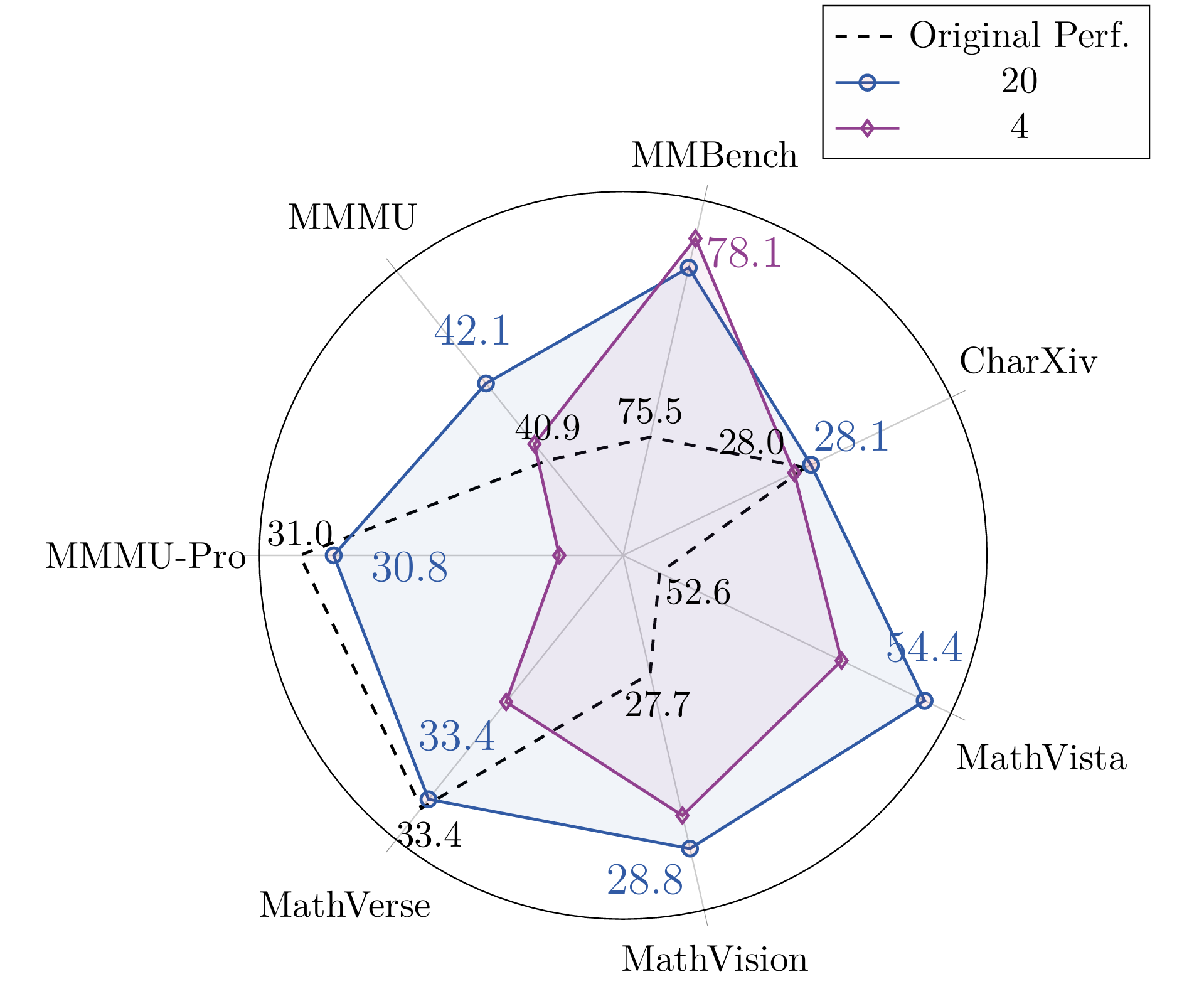
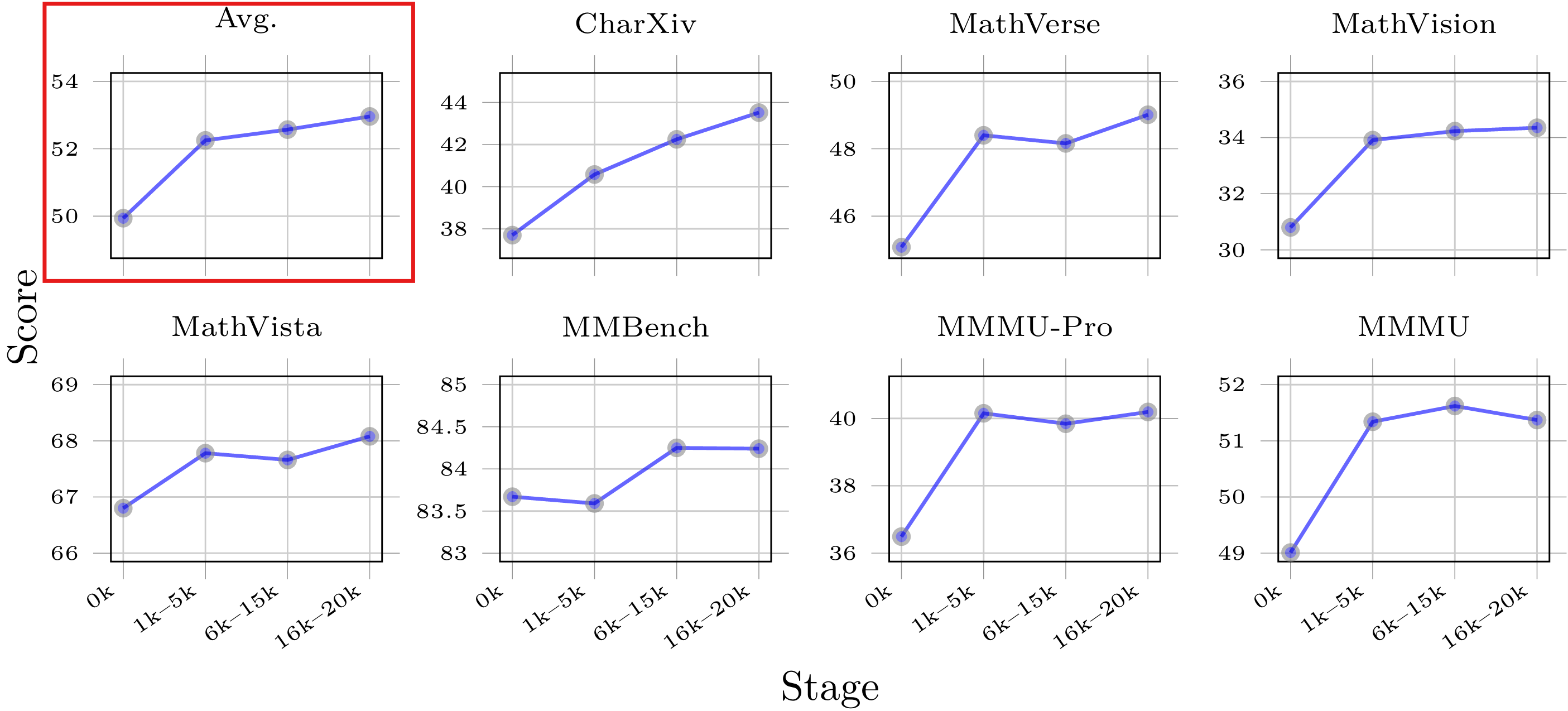
Data Volume: Model's performance score demonstrates an overall upward trend on 7 general vision benchmarks as the amount of training data increases, indicating scaling up training game data volume effectively enhances the VLM's generalizable reasoning abilities.
Citation
@article{tong2025game,
title={Game-RL: Synthesizing Multimodal Verifiable Game Data to Boost VLMs' General Reasoning},
author={Tong, Jingqi and Tang, Jixin and Li, Hangcheng and Mou, Yurong and Zhang, Ming and Zhao, Jun and Wen, Yanbo and Song, Fan and Zhan, Jiahao and Lu, Yuyang and others},
journal={arXiv preprint arXiv:2505.13886},
year={2025}
}